Please fill out this survey to let us know your thoughts on this course. Your thoughtful feedback allows us to improve future offerings of this course. Thanks!
This is not meant to be a comprehensive review of everything you need to know for the final. Please study everything (lectures, problem sets, projects, etc).
Exam info: The final exam will be on Tuesday, March 18, 2025, from 6pm-8pm. You may bring one 8.5x11" sheet of notes (front and back).
Completed 0 of X questions
Q1: Given the following code, what function must be implemented by class C1?
int main(){
C1 Obj;
double D = Obj(7);
return 0;
}
Implement the function call operator (operator()) that takes an int and returns a double.
The class C1 must overload the function call operator. For example, a correct signature would be:
double operator()(int x);
This allows an object of type C1 to be “called” with an integer parameter and return a double.
Q2: Given the code below, at the specified line what memory sections are A[0], B[1], and B in? Justify your answer.
int main(){
int A[] = {1, 2, 3};
int *B = new int[2]{9,2};
A[0] = B[1]; // At this line
delete [] B;
return 0;
}
Remember: local arrays (like A) are on the stack, and memory allocated with new is on the heap.
A[0] is part of the local array A allocated on the stack.
B[1] is an element of the array allocated on the heap (pointed to by B).
B itself is a pointer variable (local to main) allocated on the stack.
Thus, A is on the stack, the data pointed to by B is on the heap, and the pointer B is on the stack.
Q3: What is the advantage of doing Test Driven Development (TDD)? Doesn’t it just slow development by requiring tests be written first?
Consider benefits such as improved design, fewer bugs, and easier refactoring.
TDD encourages you to write tests before code, which can lead to better design and more maintainable code. It helps detect bugs early and provides a safety net for refactoring. Although it may seem to slow development initially, the overall development process is often faster and more reliable in the long run.
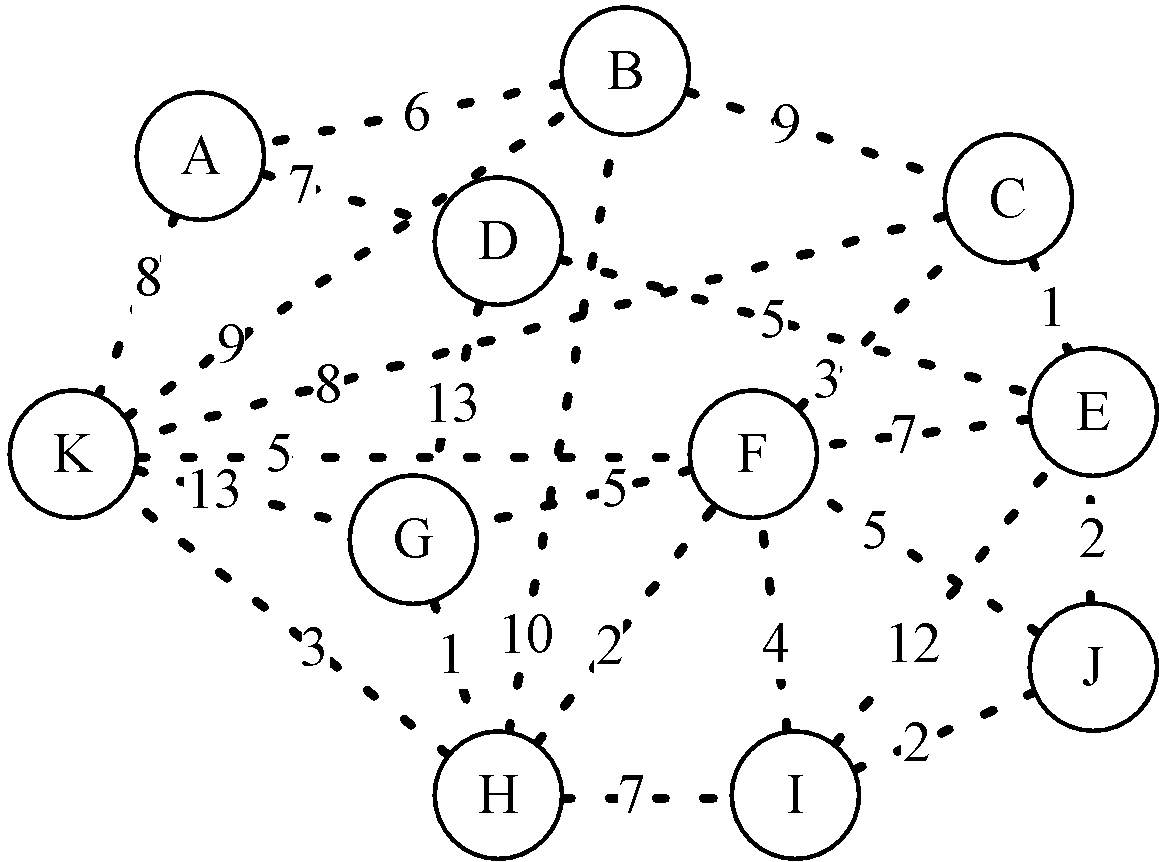
Q4: Given the following weighted undirected graph, identify the edges that are part of the minimum spanning tree and calculate its total weight.
The minimum spanning tree is obtained by selecting edges with the smallest weights while ensuring no cycles are formed. For example, using Kruskal’s algorithm, you would sort the edges by weight, then add each edge if it doesn’t form a cycle, until all vertices are connected. The total weight is the sum of the weights of these selected edges.
We will choose (C, E), (G, H), (I, J), (F, H), (E, J), (F, C), (K, H), (D, E), (A, B), (A, D) to form the MST. Total weight = 32.
See solution done in class.
Q5: The code below doesn’t compile when B is assigned 21 but compiles if 21.0 is used. What is the problem, and why does it compile one way but not the other?
The issue is due to the mismatch in types between A (double) and B (int). Changing B to 21.0 makes both doubles.
This function template requires both arguments to be of the same type T. When B is assigned 21 (an int), the two arguments to Compare have different types (double and int). Template argument deduction fails because the types do not match exactly. Using 21.0 makes both arguments double, so the template is instantiated properly and the subtraction is defined.
Q7: A software developer likes Dijkstra’s algorithm but has a graph that has negative weights (no negative cycles). The developer decides that they can just add the negative of the smallest weight to all edges and run Dijkstra’s (e.g. if smallest was -3, 3 would be added to every edge), this way the graph won’t have any negative edges. Will this approach always work, why or why not?
Consider how adding a constant to every edge affects paths with differing numbers of edges.
No, the approach does not always work. Although adding a constant removes negative edges, it distorts the relative weights of paths—especially when comparing paths with a different number of edges. Dijkstra’s algorithm relies on non-negative edge weights to guarantee that once a node’s shortest path is determined it won’t be updated. Changing the edge weights by adding a constant can cause the algorithm to choose a path that is not actually the shortest in the original graph.
Q8: The following code compiles for any type T except for bool. Why won’t it compile for bool?
std::vector<bool> is implemented differently; its elements aren’t actual bool references.
std::vector<bool> is a specialized container that does not store bool values as separate objects. Instead, it packs bits and returns proxy objects rather than actual bool references. Thus, when you try to pass AVector[0] to a function expecting a bool&, the proxy cannot be bound to a non-const reference, and compilation fails.
Q9: Given the following snippet of a Makefile, draw a Directed Acyclic Graph that represents all the files specified and which depend upon one another. Directed edges should go out from the files that are depended upon.
Q10: Given the code below, what will the value of y be and why?
int x = 3, y = 4;
auto foo = [x, &y](int a) {
y += x + a;
};
foo(5);
x is captured by value (3) and y by reference (initially 4).
After calling foo(5), y becomes 4 + (3 + 5) = 12. The lambda uses the captured value of x (3) and the reference to y, updating y accordingly.
Q12: If you need to build the interstate highway network as cheaply as possible, how would you build the network?
Consider modeling cities as vertices and highways as weighted edges.
You can model the cities and highways as a weighted undirected graph, where weights represent the cost (or distance). Then, using an MST algorithm (such as Kruskal’s or Prim’s), you can determine the set of highways that connects all cities at minimum total cost.
Q13: How do you overload the function call operator (operator()) in C++? Provide an example signature.
The syntax is similar to any member function declaration.
You overload operator() by declaring it as a member function. For example:
Q16: Write a simple function template that returns the maximum of two values.
Use the ternary operator to compare two values.
This function template returns the greater of two values.
Q17: How do lambda expressions in C++ capture variables by reference and by value? Provide a simple example.
For example, [x, &y] captures x by value and y by reference.
Lambda expressions use a capture clause. For example:
int x = 10, y = 20;
auto lambda = [x, &y](int z) {
return x + y + z;
};
Here, x is captured by value and y by reference.
Q18: What is a topological sort and in what type of graph is it applicable?
A topological sort is a linear ordering of vertices in a directed acyclic graph (DAG).
A topological sort is an ordering of the vertices in a directed acyclic graph (DAG) such that for every directed edge u → v, vertex u comes before vertex v. It is used for scheduling tasks, among other applications.
Q19: What is Breadth-First Search (BFS)? Give one example of application of BFS.
BFS explores the graph level by level and is used for finding the shortest path in unweighted graphs.
Breadth-First Search (BFS) is a graph traversal algorithm that explores vertices in layers, starting from a source vertex. It is typically used for finding the shortest path in an unweighted graph.
Q20: Describe Depth-First Search (DFS) and one application where it is particularly useful.
DFS goes deep into a branch before backtracking.
Depth-First Search (DFS) explores as far as possible along a branch before backtracking. One application is path finding in a maze -- by searching as deep as possible into the maze and backtrack when there is a dead end, DFS efficiently searches through the maze.
Q21: Briefly explain the concept of a Minimum Spanning Tree (MST) in a graph and name one algorithm used to find it.
An MST connects all vertices with minimal total edge weight. Algorithms include Kruskal’s and Prim’s.
An MST is a subset of edges in a connected, weighted undirected graph that connects all vertices with the minimum total weight. Common algorithms to find an MST include Kruskal’s and Prim’s algorithms.
Q22: What is a key limitation of Dijkstra’s algorithm and for what kind of graphs is it best suited?
Dijkstra’s algorithm does not work correctly with negative edge weights.
Dijkstra’s algorithm is best suited for graphs with non-negative edge weights. It fails or gives incorrect results when there are negative edge weights.
Q23: How can you detect if a directed graph contains a cycle? Name one method or algorithm.
Recall a graph algorithm that we discussed in class.
If a topological sort of the graph is not possible (i.e., not all vertices can be ordered), the graph contains a cycle.
Q25: How would you overload the + operator for a class representing a 2D vector? Provide a brief code snippet.
Define operator+ as a member function that returns a new object with summed components.
This overload returns a new Vector2D object whose x and y components are the sums of the corresponding components.
Q26: How would you overload the << operator to output a custom class (e.g., a Point class) to an output stream?
Use a friend function that takes std::ostream& and a const reference to your object.
class Point {
public:
int x, y;
Point(int xVal, int yVal) : x(xVal), y(yVal) {}
friend std::ostream& operator<<(std::ostream &os, const Point &pt) {
os << "(" << pt.x << ", " << pt.y << ")";
return os;
}
};
This overload allows you to write std::cout << pt; to print a Point.
Q28: How do you declare a pointer to a function that takes two ints and returns an int? Provide the syntax.
The syntax is: returnType (*pointerName)(parameterTypes);
The declaration is:
int (*funcPtr)(int, int);
This means funcPtr is a pointer to a function that takes two integers and returns an integer.
Q31: Why should a class with virtual functions also have a virtual destructor?
Without a virtual destructor, deleting a derived object through a base pointer may not call the derived destructor.
If a base class has virtual functions and is used polymorphically, its destructor should be virtual. This ensures that when you delete an object through a pointer to the base class, the derived class’s destructor is called, properly releasing resources allocated by the derived class.
Q32: What is a pure virtual function in C++ and what effect does it have on a class?
A pure virtual function is declared by assigning 0 and makes the class abstract.
A pure virtual function is declared with = 0 in a class. It makes the class abstract, meaning it cannot be instantiated and must be overridden by derived classes. For example: virtual void func() = 0;
Q33: Write a short C++ code snippet demonstrating exception handling using try, catch, and throw.
A simple example: throw an exception inside a try block and catch it.
This snippet demonstrates throwing an exception and catching it.
Q36: How would you overload the [] operator for a class that wraps an array? Provide an example signature.
The operator should return a reference to the element at the given index.
An example overload might be:
Q40: Give an example of a real-world problem that can be modeled using a Directed Acyclic Graph (DAG) and solved with a topological sort.
A common example is scheduling courses based on prerequisites.
An example is course scheduling at a university. Each course can be modeled as a node, and prerequisites as directed edges. A topological sort of the DAG gives an order in which courses can be taken without violating prerequisite requirements.
Question 2: What is the difference between a relative path and an absolute path in a UNIX file system?
One type of path starts from the root directory /, while the other starts from the current working directory.
An absolute path specifies a location from the root of the file system. It begins with /. For example, /home/user/docs/file.txt is an absolute path.
A relative path specifies a location relative to the current working directory. It does not start with /. For example, docs/file.txt refers to a file in the docs subdirectory of the current directory. The key difference is that absolute paths are always the same location no matter where you are, whereas relative paths depend on your current directory.
Question 3: Which UNIX command is used to change the permissions of a file?
It stands for "change mode".
The correct command is chmod, which stands for "change mode". For example, chmod u+x filename will add the execute permission for the file owner on filename. chmod allows you to modify read, write, and execute permissions for the user (u), group (g), or others (o).
Question 4: What does the UNIX command grep do?
It's used to search through text. For example, you might use it to find lines containing a certain word in a file.
grep is a command used to search for lines that match a given pattern in one or more files. It prints out the lines that contain the pattern. For example, grep "hello" example.txt will print all lines in example.txt that contain the word "hello". You can also use grep with other commands via pipes to filter output.
Question 5: How do you redirect the output of a command to a file, and how do you pipe the output of one command into another command?
Use the special symbols: > for redirection, and | for piping.
To redirect output to a file, you use the > operator. For example: ls > files.txt writes the output of ls into files.txt (overwriting it).
To pipe output of one command into another, use |. For example: ls | grep "txt" takes the output of ls and feeds it to grep, which then filters for lines containing "txt". Piping allows you to chain commands together.
Question 6: In a UNIX shell, what happens when you press Ctrl+Z on a running process, and how can you resume it later?
Pressing Ctrl+Z suspends (stops) the process. You can use bg or fg to continue it in the background or foreground.
Pressing Ctrl+Z sends a SIGTSTP signal to the current foreground process, which suspends (pauses) it and puts it in the background in a stopped state. To resume the process, you have two options:
Use fg to resume it in the foreground (bringing it back to active execution in the shell).
Use bg to resume it in the background (the process continues running but the shell prompt is free).
You can see stopped jobs by typing jobs, which will list background jobs and their statuses.
Question 7: Consider the following shell script. What will it do when executed?
#!/bin/bash
for f in *.txt; do
echo $f
done
The script loops through all files ending with .txt in the current directory.
This script will loop through all files in the current directory that have names ending in .txt and print each filename. In other words, it lists all *.txt files. The for f in *.txt will make $f each filename (that matches the pattern) one by one, and echo $f prints that filename to the terminal.
Question 8: How can you make a shell script (for example, script.sh) directly executable from the command line?
You need to change the file's mode to mark it as executable (using chmod).
To make a shell script executable, you need to give it execute permission. You can do this with chmod +x script.sh. This command adds the execute bit to the file's permissions. After that, if the script has a proper shebang (like #!/bin/bash at the top), you can run it directly with ./script.sh.
Question 12: Which Git command is used to stage changes (add modified or new files) so that they will be included in the next commit?
You "add" files to the staging area.
git add
Question 13: What is the purpose of unit testing in software development?
Unit tests focus on verifying that each small part of the code (each "unit" like a function or class) works correctly in isolation.
Unit testing involves writing tests for individual components (units) of a program, such as functions or classes, to ensure that each one works correctly in isolation. The purpose is to verify that each unit of the software behaves as expected for a variety of inputs and scenarios.
By doing unit testing, developers can catch bugs early, simplify debugging (because if a unit test fails, you know which component has an issue), and ensure that as the code evolves, existing functionality remains correct (regression testing). Overall, unit tests improve code reliability and make it safer to refactor or extend code, since you can quickly check if anything broke.
Question 14: Which of the following tools is specifically used to detect memory leaks and memory errors in C/C++ programs?
One popular tool for this purpose is called "Valgrind".
Valgrind is a widely-used tool for detecting memory leaks and memory errors. To use it, you'd run your program under Valgrind (for example, valgrind ./myProgram), and it will report issues like memory leaks (allocated memory not freed), uses of uninitialized memory, and invalid memory accesses.
Other tools and sanitizers also exist (for example, AddressSanitizer in modern C++ compilers), but Valgrind is a common choice for thorough checking without needing to recompile the program.
Question 16: How would you allocate an array of 10 integers on the heap in C?
You'd use malloc in C (remember to include <stdlib.h>). The size should be 10 times the size of an int.
In C, you can allocate an array of 10 integers on the heap using malloc. For example:
int *arr = malloc(10 * sizeof(int));
This allocates space for 10 int values and returns a pointer (arr) to the first element. After using the array, you should free the memory with free(arr) to avoid a memory leak. (Also, in C you'd #include <stdlib.h> to use malloc.)
In C++, you could alternatively do: int *arr = new int[10]; and later delete[] arr;, but malloc/free is the C way.
Question 17: How do strings in C (character arrays) indicate the end of the string?
They use a special null character.
C strings are arrays of characters terminated by a special character '\\0' (null character). This null terminator marks the end of the string. Functions that work with C strings (like printf, strcpy, etc.) rely on this \\0 character to know where the string ends in memory. For example, the string "Hello" in C would be stored as 'H' 'e' 'l' 'l' 'o' '\\0' in a char array.
Question 18: Write a C struct definition for a Student that has two fields: a name (string) and a GPA (floating-point).
Use the struct keyword. The name can be represented as a character array (e.g., 50 chars) or a char pointer.
A possible C struct definition for a Student could be:
struct Student {
char name[50]; // assuming name max length 49 chars + 1 for '\\0'
float gpa;
};
This defines a Student struct with a character array name (of length 50 in this case) to hold the student's name, and a float for the GPA. Note that if the name might be longer or dynamic, you could use char *name and allocate memory for it, but using a fixed array is simpler here.
Question 19: In a C/C++ program, what's the difference between including a header with #include <...> and #include "..."?
Headers included with <> are looked for in system include paths (like standard libraries), while quotes look in the local directory first.
The difference lies in where the preprocessor looks for the header file:
#include <filename> is typically used for system or library headers. The compiler (preprocessor) will search for filename in the system include directories (like those for standard library headers or other libraries installed on the system). It does not usually search the local directory of your project.
#include "filename" is typically used for header files that are part of your own program (your source files). The preprocessor will first look in the current directory (or wherever the source file is located) for filename. If it doesn't find it there, it may then fall back to searching the system include paths (this behavior can vary with compiler settings).
In short, <...> is for system headers, and "..." is for local/project headers.
Question 20: What is a memory leak in the context of C/C++ programming, and how can it be prevented?
It happens when allocated memory is never freed. Prevention involves freeing memory or using smart pointers (in C++).
A memory leak occurs when a program allocates memory (for example, with malloc in C or new in C++) and then loses all references to that memory without freeing it. The result is that the allocated memory remains unusable (still allocated, but the program can't use or free it) until the program terminates. Over time, especially in long-running programs or in loops, memory leaks can cause a program to consume more and more memory.
To prevent memory leaks in C, every allocation (using malloc) should have a corresponding free when the memory is no longer needed. In C++, every new should eventually be matched with a delete (and new[] with delete[]). Using smart pointers (like std::unique_ptr or std::shared_ptr) in C++ is another way to automatically manage memory and avoid leaks, because they free the memory when they go out of scope.
Question 23: What is polymorphism in C++ and how do virtual functions enable it?
Polymorphism allows a base class pointer to call derived class methods. In C++, you achieve this by declaring methods virtual in the base class.
Polymorphism in C++ (specifically runtime polymorphism) is the ability for a pointer or reference to a base class to actually refer to objects of derived classes and to call the derived class's methods. In simple terms, one interface (base class) can have multiple implementations (derived classes), and the correct implementation is chosen at runtime based on the actual object type.
C++ supports this via virtual functions. If a method in the base class is marked virtual and overridden in derived classes, then when you call that method on a base pointer/reference, the derived class's override is invoked (assuming the pointer actually points to a derived object). This is called dynamic dispatch.
For example, suppose you have a base class Shape with a virtual void draw() method, and classes Circle and Square inherit from Shape and override draw(). If you do:
Shape* s = new Circle();
s->draw();
The program will call Circle's implementation of draw() at runtime, even though s is a Shape*. This is polymorphism. Without virtual functions, C++ would use static (compile-time) binding and call the base class version of the function instead.
Question 26: What is encapsulation in object-oriented programming, and how does C++ support it?
Encapsulation is about restricting direct access to an object's data. C++ supports it with access specifiers (private, protected, public).
Encapsulation is the object-oriented principle of bundling data and the methods that operate on that data into a single unit (a class), and restricting direct access to some of the object's components. The idea is that an object controls its own state, and external code should interact with it only through its public interface, not by directly modifying its internals.
C++ supports encapsulation through access specifiers: public, protected, and private. By marking class members private, you hide those implementation details from outside code - they can't be accessed or modified directly from outside the class. The class can provide public member functions (methods) to allow controlled access to its data or to perform operations. This way, the internal representation of the data can change without breaking outside code, as long as the public interface remains the same.
For example, a class might keep a variable private, but provide public getter/setter functions to read or modify it. This allows the class to enforce any rules or constraints when the value changes, which wouldn't be possible if external code could just change the variable directly.
Question 27: Briefly explain the difference between public inheritance and private inheritance in C++.
With public inheritance, the derived class is a subtype of the base ("is-a" relationship) and inherits the interface. With private inheritance, the base's public members become private in the derived class, so it's more for implementation reuse and not an "is-a" relationship.
In C++, when class Derived inherits from class Base, the inheritance can be specified as public, protected, or private. The most common are public and private inheritance, which differ in how the base class's members are treated and how the relationship is viewed:
Public inheritance: This represents an "is-a" relationship. All public members of Base become public members of Derived (and protected stay protected in Derived). This means outside code can use Derived wherever Base is expected (substitutability). For example, if Dog publicly inherits Animal, a Dog* can be used in places expecting an Animal*. Public inheritance is the standard way to achieve polymorphism.
Private inheritance: This does not represent an "is-a" relationship in terms of interface. When Derived privately inherits Base, all public and protected members of Base become private in Derived. This means that outside code cannot use Base-class methods or members on a Derived object. Private inheritance is more like saying Derived is implemented in terms of Base, but not that it is a kind of Base. It's typically used for code reuse when you want to use some functionality of the base class internally, but do not want to expose the base class interface as part of the derived class's public API.
In summary, public inheritance implies a subtype relationship (and is used for polymorphism), whereas private inheritance is purely an implementation detail (the outside world doesn't see the base class in the derived class's interface).
Question 28: Explain what happens when you compile and link a C++ program that consists of multiple source (.cpp) files and header files.
Each .cpp file is compiled independently into an object file. Then the linker combines the object files together (and with libraries) to make an executable.
When you have multiple source files, the build process typically has two main stages: compilation and linking.
Compilation: Each .cpp file (translation unit) is compiled independently by the compiler. The compiler processes the source code (after the preprocessor handles #include directives, which literally insert header file contents into the code). The result of compiling a .cpp file is an object file (usually with a .o or .obj extension). This object file contains machine code and references to functions/variables that may be defined elsewhere. At this stage, the compiler checks for syntax errors and uses the declarations in header files to ensure that function calls and data types match up, but it doesn't yet resolve references to things defined in other source files.
Linking: After each .cpp is compiled to an object file, the linker takes all the object files and links them together to produce the final executable (or library). The linker resolves references between the object files. For example, if file1.cpp called a function foo() that was defined in file2.cpp, the object file from file1 will have an unresolved reference to foo, and the object file from file2 will have foo defined; the linker matches these up. The linker also brings in library code (like the C++ standard library or other libraries you're using) to resolve external references. If any function or variable is declared (for example via a header) but not defined anywhere, the linker will error out with an "undefined reference" type error.
In summary, each source file is compiled on its own into machine code with placeholders for missing pieces, and then the linker combines all those pieces and fills in the placeholders to make a complete program.
Question 30: What is a template in C++ and give an example of a simple function template.
Templates allow writing generic code. For example, a function template add that adds two elements of any type.
A template in C++ is a blueprint for generating functions or classes for different data types. It allows you to write generic code that works with any type, and the compiler generates the specific version of the code for the types you use. There are function templates and class templates (and more specialized templates), but as an example, consider a function template:
// A simple function template to add two values of the same type
template<typename T>
T add(T a, T b) {
return a + b;
}
Here add is a template that can add two values of any type T (as long as the + operator is defined for that type). You could call add<int>(3, 5) which returns 8, or add<double>(2.5, 1.1) which returns 3.6, etc. The compiler will instantiate the appropriate version of add based on the types.
The C++ Standard Template Library (STL) makes heavy use of templates. For instance, std::vector<T> is a class template that generates a vector for whatever type T you need (like std::vector<int>, std::vector<std::string>, etc.).
Question 28: How do you access command line arguments in C++? Give example code.
In your main() function, you can accept command line arguments as a parameter.
int main(int argc, char* argv[]). argc is the number of arguments. argv[] is the array of actual arguments.